Simulation data
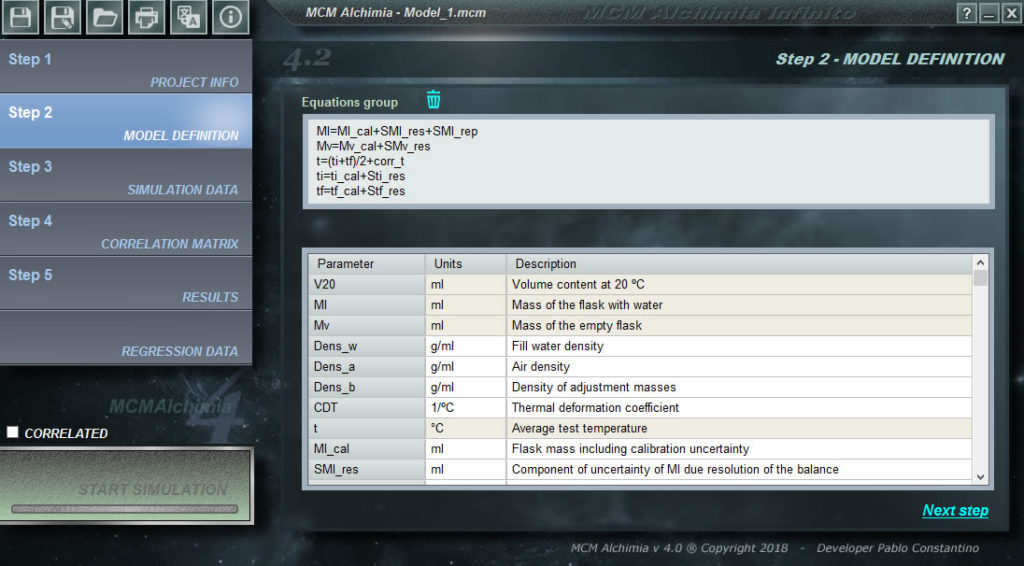
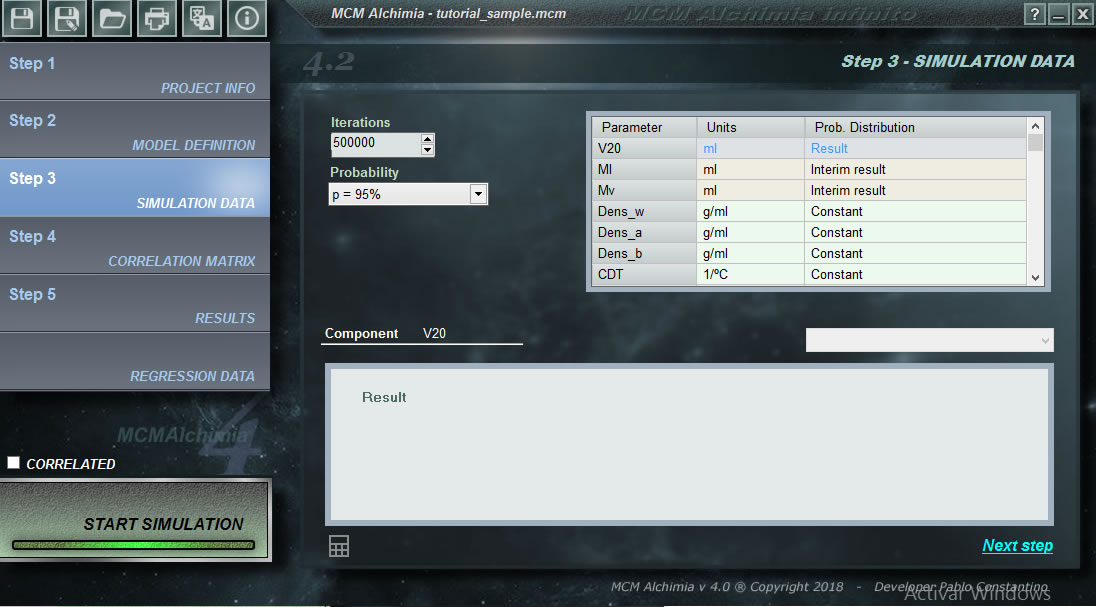
The only thing left for us to do in our first project is to assign a probability distribution function to each random variable that represents our project. As seen in the program, the grid is composed of several rows, some of them with a white background, and others with a gray background. The rows that have a gray background correspond to magnitudes for which a distribution function can not be assigned, because they are intermediate results or the final result, that is, magnitudes that will be obtained in the simulation as a result of secondary equations.
The lower part of the work panel has a command box that will give us a dropdown list of probability distribution functions so that we can select the one that fits the input magnitude. After we have selected a probability distribution, the lower box will ask us to type the necessary parameters to perform the simulation. Therefore the process of this step would be as follows:
- It is recommended to leave the number of iterations in 500 000 since it is obtained in excellent performance in the application and the results are absolutely reliable with this number of iterations (can be consulted the paper: Computational Aspects in the Estimation of Test Uncertainties by the Monte Carlo Method (Spanish only)
- We select the probability of coverage for the results. It is recommended to use 95.45% in order to obtain results for K = 2.
- We click on the first row with white background (or we reach it with the cursor keys of our keyboard)
- We select a probability distribution function in the drop-down list.
- We fill the simulation parameters in the lower panel (please, take units into account).
- We click on Apply. If everything is correct, the row will have a green background, indicating that the magnitude has its simulation data correctly assigned.
Going back to our volumetric flask we will have so:
- V20 : Disabled because it is Result, it is not possible to assign an PDF(Probability Distribution Function)
- Ml : Disabled because it is Intermediate result, It is not possible to assign a PDF
- Mv : Disabled because it is Intermediate result, It is not possible to assign an PDF
- Dens_w : We will assign the PDF Constant with a Value = 0.99829 (g / ml)
- Dens_a : Assign the PDF Constant with a Value = 1.2E-3 (g / ml)
- Dens_b : We will assign the PDF Constant with a Value = 8,000 (g / ml)
- CDT : Assign the PDF Constant with Value = 3.3E-6 (1 / ºC)
- t : Disabled because it is Intermediate result, It is not possible to assign an FDP
- Ml_cal : Due to an expanded uncertainty, we will assign the PDF Normal with the average value of our readings, Mean = 162,416, entering the certificate information in “Use certificate “, with uncertainty = 0.0047 (g) and k = 2
- SM_res : We will assign a PDF Rectangular , with Mean = 0 (corresponding to all the variables that are entered only for the purpose of estimating uncertainties) and Half interval = 0.0005 , that is, half of the division of the digital weighing scale.
- SM_rep : For repeatability, MCM Alchimia provides an experimental PDF where we can directly put the measured values and the application will be responsible for making the statistical calculations necessary for us, to use for simulation. As it is only for uncertainty purposes we will have to select “Force Mean = 0”. We will use the “Direct” option and clicking on the Values button we will enter the 5 readings of our essay: 162,384; 162,431; 162,409; 162.417; 162,439
- Mv_cal : Due to an expanded uncertainty, we will assign the PDF Normal with a mean in the reading of the balance in order to weigh the empty flask, Mean = 62.651, entering the certificate information in “Use certificate”, with uncertainty = 0.0047 (g) and k = 2
- SMv_res : We will assign a PDF Rectangular , with Media = 0 and Half interval = 0.0005.
- ti : Disabled because it is Intermediate result, It is not possible to assign a PDF
- tf : Disabled because it is Intermediate result, It is not possible to assign a PDF
- corr_t : We will assign the PDF Constant with Value = -0.022 (ºC)
- ti_cal : Because it comes from a calibration certificate, we will assign the PDF Normal with the value of our reading of the mean thermometer = 20.05. At the same time we will select “Use certificate” and we will put the expanded uncertainty = 0.021 (ºC) and k = 2.
- Sti_res : For this measure we use a mercury thermometer in division glass: 0.1ºC, from which we can visually estimate 1/4 of the division. According to this, we will assign a Triangular distribution with Mean = 0 and half-interval = 0.125 (this is estimate / 2)
- tf_cal : The same is the case as in ti_cal but now our average will be the final temperature: Mean = 20,075, select “Use certificate” and indicate the expanded uncertainty = 0.021 (ºC) and k = 2.
- Stf_res : Same as Sti_res, that is, Triangular with Media = 0 and semi-interval = 0.125.
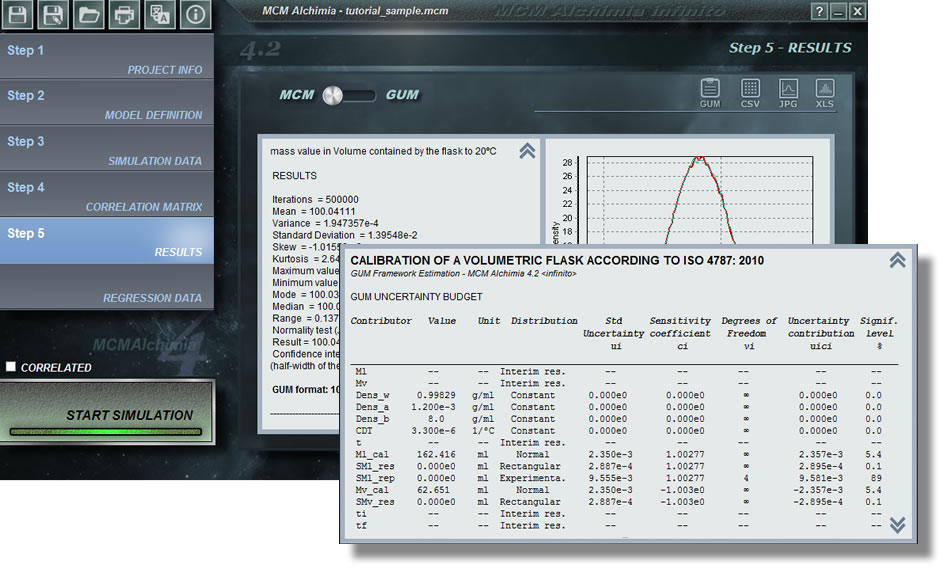
When entering data for the last magnitude, the “Run the simulation” button will light up so that we can run our simulation and obtain the results. Watch results after simulation .
More help