
Funktionen REG_x (y) und REG_y (x)
 Zum Öffnen der Funktionstastatur klicken Sie auf den Link f(x) , der sich im Gleichungseditor befindet, wenn Sie uns darauf positionieren.
Zum Öffnen der Funktionstastatur klicken Sie auf den Link f(x) , der sich im Gleichungseditor befindet, wenn Sie uns darauf positionieren.
Im unteren Bereich der Funktionstastatur befinden sich zwei Interpolationsschaltflächen, mit denen Sie lineare Interpolationsergebnisse in der verbundenen Kurve erhalten können. Diese generischen Variablen führen nicht nur die Interpolation in der Kurve durch, sondern führen auch die Abschätzung der Unsicherheit durch, indem sie ihren Beitrag zum Modell integrieren.
Es ist wichtig zu verstehen, dass diese Berechnung nicht das darstellt, was normalerweise manuell durchgeführt wird, sondern alle in der Simulation des Modells verfügbaren Werkzeuge sowie die Daten, die während der Simulation der verbundenen Kurve erhalten werden.
REG_y (x). Interpoliert die beobachtete Antwort ( y ) eines angezeigten Werts von der x -Achse und schätzt die damit verbundene Gesamtunsicherheit. Der Wert von x kann numerisch sein, eine Variable oder sogar ein Teil der Modellgleichung. Zum Beispiel REG_y (5), REG_y (A) oder REG_y (coef_a * ABS (A1-A2)).
REG_x (y). Bei einem Wert, einer Variablen oder einem Fragment der Gleichung, die der y -Achse entspricht, interpolieren und schätzen Sie die zugehörige Unsicherheit des entsprechenden Werts von x .
Unsicherheit der Interpolation.
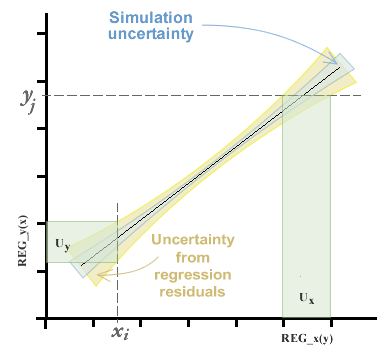
Im Kapitel Verwenden des Kalibrierungskurvenfelds haben wir gesehen, dass wir schätzen können die Kurve der besten Anpassung durch die Methode der gewöhnlichen, inversen und der Summe der kleinsten Quadrate (letztere mittels der Analysemethode der Hauptkomponente). Welche Methode auch immer gewählt wird, wir erhalten Koeffizienten der Geradengleichung zusätzlich zu einem Bereich variabler Unsicherheit entlang der Kurve, der sich aus der Unsicherheit der Simulation zusammensetzt und der durch die Varianz der Residuen beigetragen wird. Dieses Thema wird im Kapitel über Regressionen und Kurven ausführlicher behandelt.
Die Unsicherheit bei der Interpolation wird dann durch den Standardfehler der Kurve in der Achse angegeben, von der sie zu interpolieren beabsichtigt.
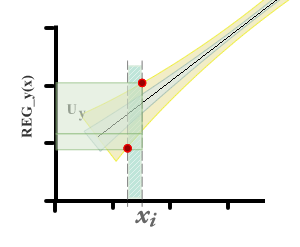
Es ist ersichtlich, dass es zwei Unterschiede in Bezug auf das Verfahren gibt, das üblicherweise zum Schätzen der Unsicherheit in Kalibrierungskurven verwendet wird. Erstens wird auf der x -Achse keine Nullunsicherheit erwartet.
Wenn Sie dagegen den Wert von x i aus einem y i
Regressionen verwenden
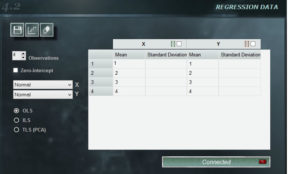 Das Regressionspanel von MCM Infinite Alchimia bietet große Flexibilität beim Erstellen einer Kalibrierungskurve für unser Testmodell.
Das Regressionspanel von MCM Infinite Alchimia bietet große Flexibilität beim Erstellen einer Kalibrierungskurve für unser Testmodell.
Panel-Funktionen
1. Menütasten Im oberen linken Bereich des Bedienfelds befinden sich drei Schaltflächen, die für dieses Bedienfeld eindeutig sind.
![]() Speichern. Ermöglicht das Speichern der für die Kurve eingegebenen Daten. Diese Daten werden unabhängig vom Modell gespeichert. Auf diese Weise können Sie dieselbe Kurve in anderen Modellen verwenden und umgekehrt bei Bedarf andere Kalibrierungskurven in demselben Modell. Die Kurven werden mit der Erweiterung .mcr gespeichert.
Speichern. Ermöglicht das Speichern der für die Kurve eingegebenen Daten. Diese Daten werden unabhängig vom Modell gespeichert. Auf diese Weise können Sie dieselbe Kurve in anderen Modellen verwenden und umgekehrt bei Bedarf andere Kalibrierungskurven in demselben Modell. Die Kurven werden mit der Erweiterung .mcr gespeichert.
![]()
Kurve öffnen. Mit dieser Schaltfläche können Sie eine zuvor gespeicherte MCM-Alchimia-Kurve öffnen. Das Öffnen einer Kurve bedeutet nicht, dass sie verbunden ist. Nach dem Öffnen müssen Sie die Verbindungstaste drücken, um die Verbindung herzustellen.
![]() Daten löschen. Löscht alle im Panel eingegebenen Daten.
Daten löschen. Löscht alle im Panel eingegebenen Daten.
2. Anzahl der Beobachtungen. Mit den Schaltflächen „Vorwärts“ und „Zurück“ kann die Anzahl der Beobachtungen, die zum Definieren der Kurve verwendet werden, geändert werden. Die Software bietet standardmäßig 5, aber eine unbegrenzte Anzahl von Beobachtungen kann mit mindestens 3 angezeigt werden.
3. Mit Null abfangen. Die Auswahl dieser Option führt unabhängig von den Eingabewerten zu einem unabhängigen Ausdruck = 0. In bestimmten Situationen kann diese Einschränkung durch die Kenntnis des Prozesses definiert werden, für den diese Option verfügbar ist.
4. Verteilungsmenü. In der oberen rechten Ecke dieses Fensters befinden sich die Dropdown-Menüs, in denen Wahrscheinlichkeitsverteilungen sowohl für den unabhängigen als auch für den abhängigen Begriff ausgewählt werden können. Die in diesen Kombinationen verfügbaren Verteilungen sind: Konstant, Rechteckig, Dreieckig und Normal.
Wenn Sie Konstante auswählen, gehen Sie davon aus, dass die Einträge auf dieser Achse keine Unsicherheit haben, sodass die Eigenschaftsspalte inaktiv ist und keine Daten eingegeben werden können. In anderen Fällen sollte die Standardabweichung für den Fall der Normalverteilung oder das Halbintervall für das Rechteck oder das Dreieck festgelegt werden.
5. Datenfenster. In diesem Feld geben Sie die Durchschnittswerte von x und y sowie ein Die Eigenschaften der Verteilung wählen wir für jede Achse aus. Wichtig! In diesem Fenster können Sie Daten aus einem Arbeitsblatt mit demselben Formular kopieren und einfügen. Wenn der kopierte Bereich größere Abmessungen hat als im Datenbereich angegeben, werden die verbleibenden Daten abgeschnitten. Die im Panel ausgewählte Zelle ist die obere linke Zelle des kopierten Bereichs.
In der Titelzelle jeder Achse befindet sich ein Kontrollkästchen. Durch Drücken dieses Kästchens werden die Daten der ersten Datenzeile dieser Achse in alle folgenden Zeilen kopiert.
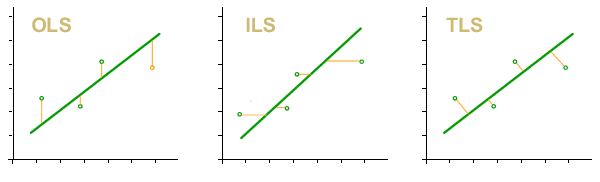
6. Minimaler Quadratwähler. In diesem Selektor wählen wir die Art der Methode der kleinsten Quadrate, mit der die Kalibrierungskurve erhalten wird.
- OLS. Gewöhnliche kleinste Quadrate. Die durch diese Methode erhaltene Kurve ist die Kurve, für die die quadratische Summe der Residuen in y minimal ist.
- ILS. Inverse Least Squares. Die durch dieses Verfahren erhaltene Kurve ist die Kurve, für die die quadratische Summe der Residuen in x minimal ist.
- TLS (PCA). Gesamtanzahl der Quadrate. Die durch dieses Verfahren erhaltene Kurve ist diejenige, für die die quadratische Summe der orthogonalen Residuen der Kurve minimal ist.
Regressionen und Kalibrierungskurven
Wichtig: : In diesem Artikel und daher bei der Verwendung des Werkzeugs für Kurven von MCM Alchimia werden die Annahmen im Zusammenhang mit der Anwendung von Least nicht berücksichtigt Quadrate wie Normalität, Linearität, Homoskedastizität und Unabhängigkeit. Durch das Studium und die Validierung dieser Annahmen können wir die Qualität und die Anwendbarkeit der linearen Darstellung aus den Eingabedaten kennen. MCM Alchimia erlaubt jedoch das Verbinden von Kurven aus beliebigen Eingabedatensätzen, die nicht platzierte kleinste Quadrate ausführen, und stellt keine Übereinstimmung mit diesen Daten sicher diese Annahmen.
Es ist üblich, Studien, Analysemethoden oder Kalibrierungen zu finden, die auf der Messung auf verschiedenen Ebenen des Analyten oder an verschiedenen Positionen der Ableseskala basieren, wenn es sich um ein Instrument handelt. Auf diese Weise wird in den meisten Fällen eine lineare Beziehung zwischen ihnen berücksichtigt, wobei durch die Methode der kleinsten Quadrate die Koeffizienten der Gleichung der Linie erhalten werden: ![]()
Auf diese Weise kann bei der Gerätekalibrierung und der Aufzeichnung der Korrektur anhand der Ableseskala dieser Wert leicht durch Anwenden der obigen Gleichung aus den durch die kleinsten Quadrate erhaltenen Koeffizienten und das Ablesen ermittelt werden.
Es ist aber auch insbesondere im Bereich der Chemie üblich, die Eichkurve mit zertifizierten Referenzmaterialien bekannter Konzentration zu konstruieren und diese Kurve dann zu verwenden, um die Konzentration eines Analyten aus einer beobachteten Antwort zu erhalten.
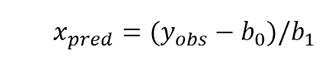
Bei der Analyse der kleinsten Quadrate gibt es drei Arten von Unsicherheiten, die mit der Kurve zusammenhängen.
- Zufällige Fehler in Referenzantworten yi .
- Zufällige Auswirkungen auf Referenzwerte xi .
- Mit der Vermutung der Linearität verbundene Wirkung, die durch die Abfälle gegeben wird.
Wenn die Werte xi und yi Wenn sie keine Unsicherheit darstellen, wird die Kurve diejenige sein, die die Quadrate des Abfalls minimiert. Bei zufälligen Fehlern in Bezugswerten xi und yi größer als Null ist, ist es möglich, Pseudo-Randomisierungen mit der jedem Parameter zugeordneten Verteilung zu erzeugen, wobei für jeden Datensatz eine Kurve durch kleinste Quadrate erhalten wird. Dies erzeugt zusätzlich zu der durch die Residuen bestimmten Unsicherheit eine zusätzliche Unsicherheit in den Regressionskoeffizienten.
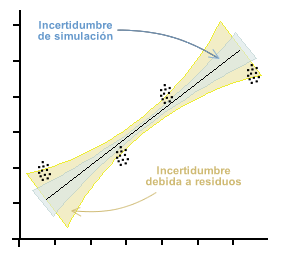
In der folgenden Grafik wird der Punktstrahl, den jede Beobachtung darstellen würde, wenn in beiden Achsen eine erhebliche Unsicherheit besteht, symbolisch dargestellt. Diese Situation ergibt daher ein Kurvenbündel, das die kleinsten Quadrate der Residuen erfüllt, wodurch Unsicherheit in beiden Regressionskoeffizienten erzeugt wird. Diese Unsicherheit ist in der Grafik blau markiert.
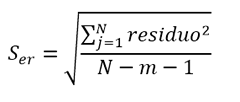
Darüber hinaus wird diese Unsicherheit um die der Kurve inhärente Unsicherheit erhöht, die in Abhängigkeit von der Standardabweichung der Restfehler bestimmt wird. Diese Unsicherheit ist im Allgemeinen größer als die der Simulation und wird durch die orangefarbene Zone in der Grafik dargestellt.
Was macht MCM Alchimia beim Verbinden einer Kurve?
Nachdem alle Werte in das Feld eingegeben wurden, müssen Sie die Kurve mit der dafür vorgesehenen Schaltfläche „verbinden“, um die Kurve in unserem Modell verwenden zu können. In diesem Fall führt MCM Alchimia eine Simulation mit dem Datensatz durch und führt eine Zufallsstichprobe mit den Eingangsdaten und der Antwort durch. Für jede der Iterationen werden die Regressionskoeffizienten b0 und b1 und ein Wert des Bestimmungskoeffizienten R2 erhalten.
Wie in der traditionellen Simulation wird eine Datenpopulation für diese Parameter mit unbekannter Verteilung erhalten und hängt von den Verteilungen und Werten der Eingabedaten ab.
Um Annahmen oder unzureichende Näherungen über diese statistischen Eigenschaften nicht zu treffen, behält MCM Alchimia die Menge der Werte in Vektoren bei, die diesen Zufallsvariablen zugeordnet sind, die während des gesamten Prozesses verfügbar sind.
Auf der anderen Seite berechnet die Anwendung mit den Durchschnittswerten jedes Paars von Eingangsdaten die Unsicherheit der Kurve als Funktion der Regressionsrückstände.
Dieses Repository für Stichprobendaten wird gemäß den Erfordernissen unseres Modells verwendet, um entweder die Koeffizienten b0 und b1 mit ihrer Unsicherheit zu verwenden, um die Unsicherheit des Kurve oder um die Interpolationsfunktionen zu verwenden, die später beschrieben werden.
Korrelierte Variablen
 Häufig werden Testmodelle verwendet, die zwei oder mehr Größen mit einem gewissen Korrelationsgrad enthalten, d. h. systematisch, wenn der Wert einer der beiden geändert wird, nimmt die andere zu oder ab. Die Korrelationskoeffizienten zwischen zwei Variablen variieren zwischen -1 und 1, wobei der Wert die Stärke der Korrelation angibt, während das Vorzeichen die Richtung angibt. Auf diese Weise verstehen wir, dass, wenn die Korrelation = 1 ist, eine absolute direkte Proportionalität zwischen den Beträgen besteht, während bei einem Wert von -1 die Proportionalität umgekehrt ist. Andererseits zeigt ein Nullwert für den Korrelationskoeffizienten an, dass die Variablen unabhängig sind.
Häufig werden Testmodelle verwendet, die zwei oder mehr Größen mit einem gewissen Korrelationsgrad enthalten, d. h. systematisch, wenn der Wert einer der beiden geändert wird, nimmt die andere zu oder ab. Die Korrelationskoeffizienten zwischen zwei Variablen variieren zwischen -1 und 1, wobei der Wert die Stärke der Korrelation angibt, während das Vorzeichen die Richtung angibt. Auf diese Weise verstehen wir, dass, wenn die Korrelation = 1 ist, eine absolute direkte Proportionalität zwischen den Beträgen besteht, während bei einem Wert von -1 die Proportionalität umgekehrt ist. Andererseits zeigt ein Nullwert für den Korrelationskoeffizienten an, dass die Variablen unabhängig sind.
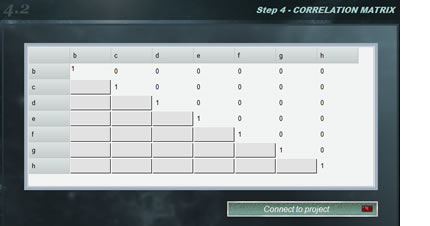
Wenn wir die Korrelationskoeffizienten zwischen den Größen des mathematischen Modells unseres Versuchs kennen, können wir das Korrelationspanel verwenden. Die Korrelationsmatrix wird automatisch mit den Variablen unseres Modells erstellt, sodass wir den Korrelationskoeffizienten zwischen ihnen angeben. Wenn Sie die Matrix fertiggestellt haben, klicken Sie auf < Mit dem Projekt verbinden >. Nachdem Sie überprüft haben, dass die Matrix korrekt ist, zeigt das grüne Licht der Schaltfläche an, dass sie verbunden ist.
In diesem Fall wird die Simulation mit korrelierten Variablen durchgeführt. Wenn Sie zu einem beliebigen Zeitpunkt wieder mit unabhängigen Größen arbeiten möchten, müssen Sie nur das Kontrollkästchen < korreliert > auf der Simulationsschaltfläche deaktivieren. Auf diese Weise können wir zwischen beiden Zuständen wechseln, ohne die Korrelationsmatrix jedes Mal zu korrigieren.
Regression
HINWEIS: Dieses Werkzeug ist nur für Modelle mit verbundenen Kurven verfügbar (siehe Arbeiten mit Kurven)
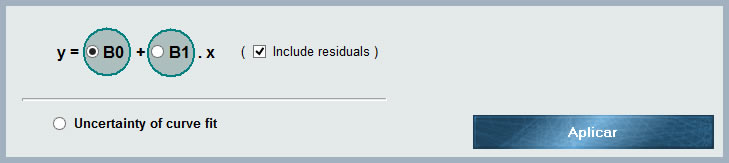
Am Ende der Verteilungsliste hat MCM Alchimia dieses Tool verfügbar, mit dem Regressionsparameter unserem Testmodell zugewiesen werden können. Auf diese Weise haben wir drei Optionen für unsere verbundene Kurve zur Auswahl:
- B0. Unabhängiger Koeffizient (Ordinate am Ursprung) der verbundenen Kurve.
- B1. Koeffizient erster Ordnung der verbundenen Kurve.
Sowohl B0 als auch B1 weisen Unsicherheiten auf, die dem Ergebnis der Simulation entsprechen. Wenn also mindestens einer der zur Erstellung der Kurve verwendeten Werte Unsicherheiten aufweist, erzeugt die Simulation notwendigerweise eine Folge von Kurven für jeden Satz von simulierte Werte, jeweils mit den Koeffizienten B0 und B1, die einen gewissen Variationsgrad aufweisen. Die Größe dieser Variation hängt von der Größe der Unsicherheit der Eingangsdaten in beiden Achsen ab.
- Residuen einschließen Wenn diese Option ausgewählt ist, werden die mit dem ausgewählten Koeffizienten (B0 oder B1) verbundenen Unsicherheiten erhöht um eine durch den Beitrag aufgrund der Residuen der kleinsten Quadrate bestimmte Menge erhöht. Daher umfasst die mit beiden Parametern verbundene Unsicherheit Simulations- und Abfallbeiträge
- Unsicherheit aufgrund von Anpassungen. Wenn wir diese Option unserem Parameter zuweisen, erhalten wir die Standardunsicherheit der verbundenen Kurve aufgrund von Residuen, die auf Null zentriert sind (nur als Beitrag der Unsicherheit). Dieser Wert wird in Regressionen gefunden, die in einer Kalkulationstabelle vorgenommen wurden, z. B. typischer Fehler oder Standardfehler der Regression.
Hinweis : Wenn Sie den typischen Fehler einer Kurve isoliert simulieren, ist das Ergebnis der Standardabweichung der resultierenden Grundgesamtheit etwas größer als der gleiche Parameter, der in einer Kalkulationstabelle erhalten wird. Dies liegt daran, dass, obwohl die Variable als Mittelwert 0 und Abweichung = zur Standardunsicherheit definiert ist, die Simulationsverteilung in MCM Alchimia für diesen Fall keine Normalität ist, sondern ein Student mit den Freiheitsgraden, mit denen die Anzahl der Punkte festgelegt wird Die Kurve wurde erstellt, was zu einer größeren Abweichung der Messgröße führte.
Experimentell (Rohdaten)
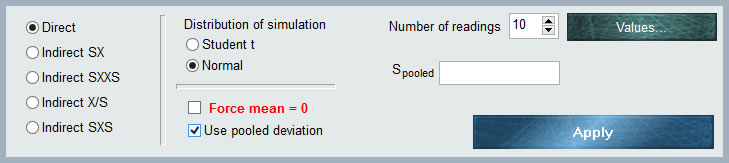
Diese Distribution ist keine Distribution an sich, sondern eine leistungsstarke und exklusive Form von MCM Alchimia, um Rohwerte der Wiederholbarkeit in das Modell unseres Versuchs einzugeben, ohne vorherige Operationen in durchführen zu müssen eine Kalkulationstabelle.
Wie aus der Grafik ersichtlich, verfügt das Eingabedatenfeld über mehrere Selektoren, um die Eingabeeigenschaften unserer Unsicherheitskomponente zu definieren.
1. Eingabedatensatz
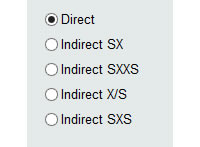 Auf der linken Seite des Bedienfelds befinden sich 5 Auswahlknöpfe (Auswahlschalter), die der Software anzeigen, in welcher Form die Eingabedaten eingegeben werden. Wir haben dann 5 Eingabeformulare:
Auf der linken Seite des Bedienfelds befinden sich 5 Auswahlknöpfe (Auswahlschalter), die der Software anzeigen, in welcher Form die Eingabedaten eingegeben werden. Wir haben dann 5 Eingabeformulare:
- Direkt. Wenn Sie diese Option auswählen, werden wir MCM Alchimia mitteilen, dass wir die Daten einzeln eingeben werden. Aus diesen Daten erhält die Software automatisch den Mittelwert, die Standardabweichung der Stichprobenmittel und die Freiheitsgrade sowie die für die Simulation erforderlichen Statistikparameter.
- Indirekter SX. Diese Option gibt an, dass die Anwendung zwei Datenspalten anfordern soll, von denen jeder Wert für die Wiederholbarkeit aus der Subtraktion Value = (X – S) abgerufen wird. Diese Option kann beispielsweise verwendet werden, wenn zwei digitale Instrumente durch Vergleich kalibriert werden und Sie die Wiederholbarkeit der Fehler berechnen möchten. Wir geben die Ablesung des Musters in der Spalte von S und die Ablesung der Probe in X an. Sie kann auch verwendet werden, wenn das Gewicht einer in einem Tiegel enthaltenen Substanz durch das Gewicht des leeren Tiegels und erhalten werden soll mit dem Inhalt. In diesem Fall können die Massenwerte des leeren Tiegels in S und die Masse des Tiegels mit dem Inhalt in X angegeben werden.
- Indirektes SXXS. In bestimmten Fällen werden die Fehlerwerte aus einer Reihe von Kennzahlen erhalten, die auch als ABBA-Format bezeichnet wird und in einer Tabelle mit 4 Spalten angefordert wird. Dieses Format wird manchmal verwendet, wenn die durch die potentielle Drift der Messinstrumente verursachte Vorspannung beseitigt werden soll. Auf diese Weise erhält man jeden Wert aus der Berechnung Wert = (X1 + X2) / 2 – (S1 + S2) / 2 .
- Indirektes X / S In diesem indirekten Format wird jeder Wert für Wiederholungen aus der Beziehung Value = X / S abgerufen. durch eine Tabelle mit zwei Spalten angegeben.
- Indirektes SXS. Dieses Format ähnelt SXXS, nur in drei Spalten. Die Werte werden automatisch von der Anwendung durch die Operation erhalten: Wert = X – (S1 + S2) / 2 .
2. Einnahme von Werten.
![]() In der oberen rechten Ecke des MCM-Bedienfelds hat Alchimia ein Feld, in dem die Anzahl der Wiederholungen angegeben werden muss, bis zu der die Simulationsparameter geschätzt werden sollen, d. h. der Mittelwert und die Standardabweichung Strümpfe Standardmäßig hat die Anwendung 10 Werte. Dieser Wert kann jedoch durch manuelles Bearbeiten der Nummer oder mit den Inkrement- / Dekrementpfeilen geändert werden.
In der oberen rechten Ecke des MCM-Bedienfelds hat Alchimia ein Feld, in dem die Anzahl der Wiederholungen angegeben werden muss, bis zu der die Simulationsparameter geschätzt werden sollen, d. h. der Mittelwert und die Standardabweichung Strümpfe Standardmäßig hat die Anwendung 10 Werte. Dieser Wert kann jedoch durch manuelles Bearbeiten der Nummer oder mit den Inkrement- / Dekrementpfeilen geändert werden.
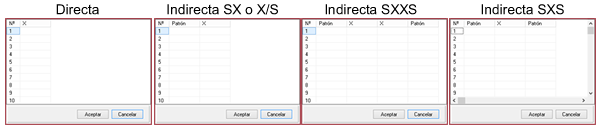
Nachdem wir die Anzahl der Messungen angegeben haben, die eingegeben werden, klicken wir auf die Schaltfläche „Werte“, wo sich ein Raster für die Eingabe von Werten öffnet. Je nach dem im Auswahlfeld für Optionsfelder ausgewählten Einkommensformat enthält die Tabelle die erforderliche Anzahl von Spalten:
3.- Simulationsverteilung.
 In diesem Abschnitt des Fensters können Sie die Simulation anhand der Parameter der zuvor definierten Verteilung anhand der eingegebenen Werte durchführen:
In diesem Abschnitt des Fensters können Sie die Simulation anhand der Parameter der zuvor definierten Verteilung anhand der eingegebenen Werte durchführen:
Studentenverteilung. Bei Auswahl dieser Option berechnet MCM Infinite Alchimia den Mittelwert und die Standardabweichung der Stichprobenmittelwerte aus der eingegebenen Wertetabelle. Dann wird eine randomisierte Verteilung entsprechend der Student-t-Funktion generiert, wobei die Anzahl der Freiheitsgrade der Anzahl der Werte -1 entspricht.
Normal. In diesem Fall führt die Software die gleichen Berechnungen wie zuvor aus und übernimmt dann den inversen Wert der Funktion t (Abdeckungsfaktor k ) für die gewählte Abdeckungswahrscheinlichkeit und die berechneten Freiheitsgrade . Die Simulation wird dann mit einer pseudo-randomisierten Normalverteilung des berechneten Mittelwerts und der Standardabweichung s1 = ks / k ‚ durchgeführt, wobei k‘ der inverse Wert der Verteilung t für die gleiche Wahrscheinlichkeit der Abdeckung, jedoch für unendliche Freiheitsgrade.
Bei einer hohen Anzahl von Freiheitsgraden weisen beide Simulationen ähnliche oder identische Eigenschaften auf. Bei einer Reihe von Freiheitsgraden dagegen <10 Die Ergebnisse beider Simulationen könnten erhebliche Unterschiede aufweisen. Welches ist dann zu wählen?
Abhängig von dem Nutzen, den wir für diese Anwendung bereitstellen möchten, benötigen wir möglicherweise die eine oder andere Simulationsverteilung, aber für Techniker, die keine Experten für Statistik sind, empfehlen wir die folgende Regel:
- Für die Validierung traditioneller Berechnungsschätzungen gemäß GUM (JCGM 101) werden Routinelabortests, Eignungsprüfungen, GUM vs MCM-Validierung usw. gemäß einer Normalverteilung simuliert.
- Für Forschung, Statistik, Wirtschaft und Fälle, in denen es erforderlich ist, den Einfluss einer Variablen auf die Unsicherheit der Messgröße genau zu kennen, simulieren Sie die Verteilung nach Student t.
4. Forcing Mean = 0.
Diese Option ist vorgesehen, wenn der Steuerpflichtige, für den diese Verteilung gilt, nur aus Unsicherheitsgründen eingegeben werden soll. Auf diese Weise wird der Durchschnittswert der Funktion aufgehoben, so dass der Mittelwert = 0 ist und keinen Wert liefert. Dies ist besonders nützlich, wenn Modellkomponenten vorhanden sind, die mehr als eine Unsicherheit aufweisen, beispielsweise Auflösung und Wiederholgenauigkeit. Auf diese Weise kann es als summierte Variable angegeben werden, eine Konstante mit dem Wert des Parameters und der Rest nur als Unsicherheitsfaktoren mit einem Nullwert. In diesem Fall kann Typ A als experimentell eingestuft werden. Das Beispiel dieser Hilfe verwendet dieses Tool.
Die Student t-Verteilung
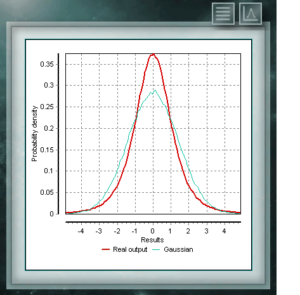 Es ist üblich, bei allen Arten von Analysen, Tests oder Kalibrierungen davon auszugehen, dass sich wiederholende Ereignisse ohne externe Stimuli, die ihre Wahrscheinlichkeiten variieren, gemäß einer durch den Mittelwert definierten Normal- oder Gaußverteilung verteilt werden und die für die Probe berechnete Standardabweichung. Genau genommen trifft dies nur zu, wenn die Anzahl der Wiederholungen groß ist, was mit dem zentralen Grenzwertsatz übereinstimmt. Wenn wir jedoch nicht über ausreichende Informationen verfügen, um die Eigenschaften dieser Gaußschen Verteilung zu beschreiben, weil unsere Untersuchungsstichprobe nicht groß genug ist, nehmen Sie diese Bedingungen an erfüllt sind, werden wir die für unsere Messung unterschätzten Unsicherheitswerte, wie im Leitfaden JCGM 100 – Leitfaden zum Ausdruck der Unsicherheit bei der Messung angegeben, sicherlich überschreiten.
Es ist üblich, bei allen Arten von Analysen, Tests oder Kalibrierungen davon auszugehen, dass sich wiederholende Ereignisse ohne externe Stimuli, die ihre Wahrscheinlichkeiten variieren, gemäß einer durch den Mittelwert definierten Normal- oder Gaußverteilung verteilt werden und die für die Probe berechnete Standardabweichung. Genau genommen trifft dies nur zu, wenn die Anzahl der Wiederholungen groß ist, was mit dem zentralen Grenzwertsatz übereinstimmt. Wenn wir jedoch nicht über ausreichende Informationen verfügen, um die Eigenschaften dieser Gaußschen Verteilung zu beschreiben, weil unsere Untersuchungsstichprobe nicht groß genug ist, nehmen Sie diese Bedingungen an erfüllt sind, werden wir die für unsere Messung unterschätzten Unsicherheitswerte, wie im Leitfaden JCGM 100 – Leitfaden zum Ausdruck der Unsicherheit bei der Messung angegeben, sicherlich überschreiten.
Das gleiche Problem wurde von William Gosset angesprochen, der aus Gründen des Geschäftsgeheimnisses des Unternehmens, in dem er arbeitete, seine Arbeit als „Student“ unterschrieb. Gosset musste aus experimentellen Daten eine Verteilung schätzen, die kleine Proben unbekannter Varianz repräsentierte. Diese von Gosset vorgeschlagene Verteilungsfunktion ist als Student t-Verteilung bekannt und reagiert auf die folgende allgemeine Gleichung:
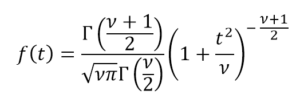
In jeder normalverteilten Grundgesamtheit ermöglicht die Student t-Verteilung die Vergrößerung der Breite der resultierenden Normalverteilung, um die mit der Messgröße verbundene Unsicherheit infolge der Informationsarmut zu erhöhen, die eine kleine Stichprobe des gesamten Loses liefert. In dem Maße, in dem diese Probe größer ist, nähert sich die Verteilung t der Normalen an, die sich aus der Standardabweichung der Probe ergeben, bis sie für unendliche Wiederholungen des Ereignisses mit dieser identisch ist.
Bei allen Arten von Analysen ist es richtig, den sich wiederholenden Ereignissen die Verteilung t mit einem Parameter gl zuzuordnen, der die Freiheitsgrade ist, deren Wert die Anzahl der Wiederholungen minus 1 ist. MCM Alchimia ermöglicht die Simulation einer Zufallsauswahl entsprechend bei der Student t-Verteilung nicht nur mit diesem Parameter der Form (Freiheitsgrade), sondern auch mit Parametern von Skalierung und Position durch die Standardabweichung bzw. den Mittelwert, so dass sie in jeder Situation, wo angemessen, mit Nein verwendet werden kann zusätzliche Operationen.
Eingabeparameter:
- Mittelwert. Dieser Parameter definiert die Verschiebung der Funktion auf der Abszissenachse. Entspricht dem Durchschnittswert der Zufallsvariablen. Die Datensammlung dieser Variablen wird daher auf beiden Seiten dieser Funktion verteilt. Bei dieser Verteilung fällt der Durchschnitt wie bei allen symmetrischen Funktionen mit dem statistischen Modus zusammen.
- Freiheitsgrade. Entspricht der Anzahl der Wiederholungen minus 1. Stellt die Anzahl der Werte dar, die variieren können, ohne den Wert des Stichprobenmittelwerts zu ändern.
- Standardabweichung. Maß der Streuung der Werte in Bezug auf den Probenmittelwert. Wenn diese Verteilung für (statistische) Unsicherheitskomponenten vom Typ A verwendet wird, kann dieser Wert gemäß der folgenden Gleichung berechnet werden:
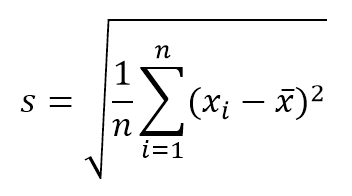
Dabei ist n die Anzahl der Werte oder Wiederholungen. Wenn Sie dagegen die Standardabweichung der Stichprobenmittel kennen möchten, erhalten Sie diesen Wert durch Teilen von s / √ n .
Konstante
Dies ist keine Verteilung streng genommen, sondern ein Wert mit einer Nullunsicherheit, wie Wasserdissoziationskonstante, Normalgewicht, Referenztemperatur eines Tests, Nennkapazität eines volumetrischen Materials usw. Es kann auch für Komponenten von verwendet werden das Modell mit mehreren Unsicherheitsfaktoren, wobei das Modell als Konstante einer Liste von Nullwertkomponenten mit unterschiedlichen Verteilungen hinzugefügt wird.
Mehr Hilfe
Dreieckige Verteilung
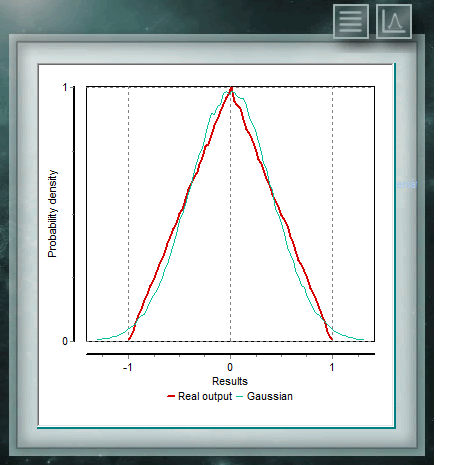 Die durchgehende Dreiecksverteilung ist dadurch gekennzeichnet, dass sie wie im Fall des Rechtecks an zwei Extreme begrenzt ist, aber auch einen Modus (oder einen wahrscheinlicheren Wert) innerhalb dieses Bereichs aufweist. Die Wahrscheinlichkeit in jedem Teilintervall gleicher Länge steigt linear bis zur Art und Weise und fällt dann auf die gleiche Weise bis zur oberen Grenze ab. Diese Verteilung wird häufig in Variablen verwendet, bei denen die Informationen begrenzt sind, wie im Fall der Uniform, bei denen jedoch eine ungefähre Kenntnis des Modalwerts vorliegt, d. H. Wo der genaue Punkt dieses Wertes nicht bekannt ist, jedoch Informationen vorhanden sind der Region oder des Teilintervalls, wo sie zu finden sind.
Die durchgehende Dreiecksverteilung ist dadurch gekennzeichnet, dass sie wie im Fall des Rechtecks an zwei Extreme begrenzt ist, aber auch einen Modus (oder einen wahrscheinlicheren Wert) innerhalb dieses Bereichs aufweist. Die Wahrscheinlichkeit in jedem Teilintervall gleicher Länge steigt linear bis zur Art und Weise und fällt dann auf die gleiche Weise bis zur oberen Grenze ab. Diese Verteilung wird häufig in Variablen verwendet, bei denen die Informationen begrenzt sind, wie im Fall der Uniform, bei denen jedoch eine ungefähre Kenntnis des Modalwerts vorliegt, d. H. Wo der genaue Punkt dieses Wertes nicht bekannt ist, jedoch Informationen vorhanden sind der Region oder des Teilintervalls, wo sie zu finden sind.
Wichtig: Bei MCM Alchimmia ist nur das zentrierte Dreieck verfügbar, dh der statistische Modus entspricht dem Durchschnittswert des AB-Intervalls.
Die allgemeine Gleichung wird dann für das Intervall AB definiert, während außerhalb dieser Extremwerte die Verteilungsfunktion 0 ist. Die Formel lautet dann:
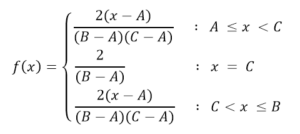
Eingabeparameter:
- Durchschnitt. Mittelwert und Modalwert der Zufallsvariablen.
- Halbintervall. Entspricht der Mitte des Intervalls, auf das diese Verteilung angewendet wird, dh (B-A) / 2, wobei A und B die oberen und unteren Grenzen des Intervalls sind. Wenn diese Funktion durch Auflösung eines Analoginstruments auf die Unsicherheit angewendet wird, entspricht dieser Parameter der Aufwertung (oder Schätzung & lt; e & gt;). Auch auf dem Gebiet der Chemie ist es üblich, die Toleranz des volumetrischen Materials oder sogar der Referenzmaterialien als Ursache für die Unsicherheit der Dreieckverteilung zu betrachten (EURACHEM / QUAM: 2012 8.1.6). In beiden Fällen entspricht das Halbintervall dem Wert und der Toleranz des Materials.
Mehr Hilfe