
Экспериментальные (необработанные данные)
 Этот дистрибутив не является само по себе распределением, а мощной и эксклюзивной формой MCM Alchimia для ввода необработанных значений повторяемости модели нашего исследования без необходимости делать какие-либо предыдущие операции в таблицу.
Этот дистрибутив не является само по себе распределением, а мощной и эксклюзивной формой MCM Alchimia для ввода необработанных значений повторяемости модели нашего исследования без необходимости делать какие-либо предыдущие операции в таблицу.
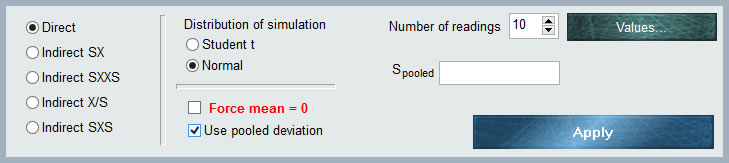
Как видно на графике, панель данных ввода имеет несколько селекторов для определения входных характеристик нашего компонента неопределенности.
1. Набор входных данных
 Слева от панели у нас есть 5 переключателей (селекторов), которые указывают программному обеспечению форму, в которую будут вводиться входные данные. Затем мы получим 5 форм ввода:
Слева от панели у нас есть 5 переключателей (селекторов), которые указывают программному обеспечению форму, в которую будут вводиться входные данные. Затем мы получим 5 форм ввода:
- Прямой. . Выбрав эту опцию, мы сообщим MCM Alchimia, что мы будем вводить данные по одному. Из этих данных программное обеспечение автоматически получит среднее стандартное отклонение выборки и степень свободы, параметры статистики, необходимые для моделирования.
- Непрямой SX. Этот параметр указывает, что мы хотим, чтобы приложение запрашивало два столбца данных, из которых каждое значение для повторяемости будет получено из вычитания Value = (X — S) . Пример, когда этот параметр можно использовать, — это когда два цифровых прибора калибруются путем сравнения, и вы хотите рассчитать повторяемость ошибок. Мы указываем считывание рисунка в столбце S и считывание образца в X. Его также можно использовать, когда желательно получить вес вещества, содержащегося в тигле, через вес пустого тигля и с содержанием. В этом случае значения массы пустого тигля можно указать в S и массу тигля с содержимым в X.
- Непрямой SXXS. В некоторых случаях значения ошибок получают из набора мер, также известного как формат ABBA, который будет запрашиваться в таблице из 4 столбцов. Этот формат иногда используется, когда требуется устранить смещение, вызванное потенциальным дрейфом измерительных приборов. Таким образом, каждое значение будет получено из расчета Значение = (X1 + X2) / 2 — (S1 + S2) / 2 .
- Непрямой X / S. . В этом косвенном формате каждое значение для повторов будет получено из отношения Value = X / S указывается через таблицу из двух столбцов.
- Непрямой SXS. Этот формат похож на SXXS, только в трех столбцах. Значения будут получены автоматически приложением через операцию: Значение = X — (S1 + S2) / 2 .
2. Доход от ценностей.
![]() В верхнем правом углу панели MCM Alchimia имеет поле, где мы должны указать количество повторений, которые мы хотим оценить параметры моделирования, то есть среднее и стандартное отклонение чулки По умолчанию приложение имеет 10 значений, однако это значение может быть изменено путем ручного редактирования номера или стрелками увеличения / уменьшения.
В верхнем правом углу панели MCM Alchimia имеет поле, где мы должны указать количество повторений, которые мы хотим оценить параметры моделирования, то есть среднее и стандартное отклонение чулки По умолчанию приложение имеет 10 значений, однако это значение может быть изменено путем ручного редактирования номера или стрелками увеличения / уменьшения.
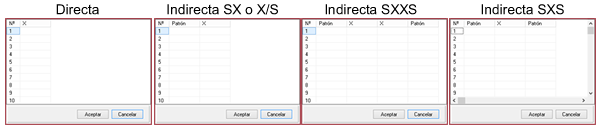
После указания количества измерений, которые будут введены, нажмите кнопку «Значения», где откроется сетка для ввода значений. В соответствии с форматом дохода, выбранным в селекторе переключателей, таблица будет иметь необходимое количество столбцов:
3.- Распределение симуляции.
 Этот раздел панели предоставляет два способа выполнения моделирования из параметров ранее определенного распределения из введенных значений:
Этот раздел панели предоставляет два способа выполнения моделирования из параметров ранее определенного распределения из введенных значений:
Распределение учеников. . При выборе этой опции MCM Infinite Alchimia рассчитает среднее и стандартное отклонение выборки из таблицы введенных значений. Затем он будет генерировать рандомизированное распределение в соответствии с функцией Стьюдента t с рядом степеней свободы, равными числу значений -1.
Обычный. В этом случае программное обеспечение будет выполнять те же вычисления, что и раньше, затем взять обратное значение функции t (коэффициент покрытия k ) для выбранной вероятности покрытия и рассчитанных степеней свободы , Затем симуляция будет выполняться с псевдослучайным нормальным распределением вычисленного среднего и стандартного отклонения s1 = ks / k ‘ , будучи k’ обратное значение распределения t при той же вероятности покрытия, но бесконечные степени свободы.
Для большого количества степеней свободы оба моделирования будут иметь сходные или идентичные характеристики. Напротив, для ряда степеней свободы <10 Результаты, полученные из обоих симуляций, могут иметь значительные отличия. Тогда какой из них выбрать?
В зависимости от утилиты, которую мы хотим предоставить этому приложению, нам может потребоваться одно или другое распределение моделирования, но для техников, которые не являются экспертами в области статистики, мы рекомендуем следовать следующему правилу:
<Ол>
4. Принудительное значение = 0.
Этот вариант предусмотрен, когда мы хотим, чтобы налогоплательщик, к которому относится это распределение, применяется только для ввода неопределенности. Таким образом, среднее значение функции будет отменено, так что среднее значение равно 0 и не дает значения. Это особенно полезно, когда у нас есть компоненты модели, которые имеют более одной неопределенности, например, разрешение и повторяемость. Таким образом, это можно указать как суммарные переменные, одну константу со значением параметра, а остальное только как вкладчики неопределенности с нулевым значением. В этом случае тип A можно поставить как экспериментальный. Пример этой справки использует этот инструмент.